提醒:本文最后更新于 2893 天前,文中所描述的信息可能已发生改变,请仔细核实。
博客服务器一直用着NodeQuery、UptimeRobot和Netdata,各司其职。
{kind=link}
虽然Netdata的功能确实齐全,但万一服务器GG了,没恢复前,是无法查阅数据,最多因为GG前有邮件提醒,有预警,而且很多数据其实并不需要去看。
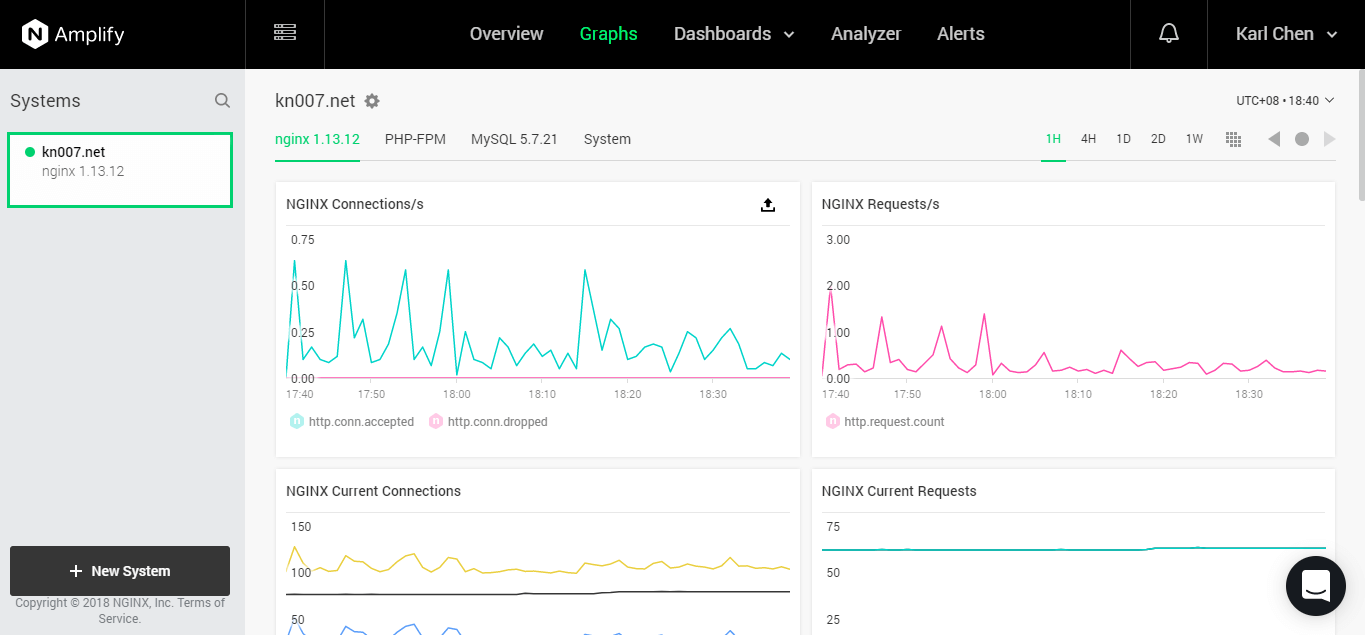
使用Amplify的原因,主要是UI高大上(但不支持移动端是个糟点,希望尽快完善)、开源、轻便,主要服务(Nginx、PHP、MySQL)的参数及系统资源监测较齐,并且完全以图表显示(更容易发现瓶颈和问题)。而且可以定制预警类型,完全可以取代Netdata并补了NodeQuery的不足(NQ只能对CPU、MEM、DISK做预警)。
虽说预警数量有限制,但完全够用。最重要的是,出现问题时,起码我在外部,能看到一些大概问题。
另外一点比较好的是Analyzer功能,(因为与Nginx深度整合)能看到Nginx的一些优化建议和问题提醒。不过貌似优化得不错,所以并没有特别需要改的。
简单来说,Nginx Amplify是个较为全面的系统监测工具。
而且之前提到给Amplify提交的两个问题,Nginx团队一直密切跟踪,解决问题。
目前两问题均已在Amplify 1.2.0-1解决了,两个问题分别是:
第一个问题:MySQL数据抓取,时间长了,数据会断,从DEBUG看是正常的,但是push到Nginx就没数据了。这个问题的原因,Nginx并未告知我。
第二个问题:PHP数据抓取有时会导致Amplify进程退出,原因是Amplify采用的FCGI去读取PHP的状态信息,当nginx.conf配有fastcgi_keep_conn时,(因为连接超时)便会导致这个情况出现。
{kind=link}
在北京时间2018年04月13日的早上6点半至8点半之间,附属服务器近2小时的流量达到1.6TB,并且使得主服务器也被跑了600GB的流量。后面还是因为主服务器的主机商发了邮件过来(文末附原文),才发现这一情况。
主服务器上的防御因为流量是从附属服务器来的,属于白名单,并没有报警。
这次处理了附属服务器与主服务器的程序机制,并且将附属服务器做相对豁免限制。
而附属服务器因为没有邮件系统,并没有及时通知。
希望下次能及时发现这种问题,而不是在收到质询函后才去被动处理。
目前已使用Amplify对服务器出网流量进行预警,下次出现异常,可以及时发现。
We have detected a traffic pattern outbound from your device which appears to be malicious in nature. The traffic coming out from device 4056CC-XEON is 445.7 Mbps. We have rate limited the device to avoid impact on the network from malicious activity. Please contact us as soon as possible to help troubleshoot this issue.
{kind=link}
转载请注明转自:kn007的个人博客的《为什么用Nginx Amplify》